Debugging & Profiling
DataFlowTasks defines two visualization tools that help when debugging and profiling parallel programs:
- a visualization of the Directed Acyclic Graph (DAG) internally representing task dependencies;
- a visualization of how tasks were scheduled during a run, alongside with other information helping understand what limits the performances of the computation.
Visualization tools require additional dependencies (such as Makie or GraphViz) which are only needed during the development stage. We are therefore only declaring those as weak dependencies (for Julia v1.9 and above). The user can either set up a stacked environment in which these dependencies are available, or use the DataFlowTasks.stack_weakdeps_env!() function which handles the environment stack automatically.
Let's first introduce a small example that will help illustrate the features introduced here:
using DataFlowTasks
# Utility functions
init!(x) = (x .= rand()) # Write
mutate!(x) = (x .= exp.(x)) # Read+Write
result(x,y) = sum(x) + sum(y) # Read
# Main work function
function work(A, B)
# Initialization
@dspawn init!(@W(A)) label="init A"
@dspawn init!(@W(B)) label="init B"
# Mutation
@dspawn mutate!(@RW(A)) label="mutate A"
@dspawn mutate!(@RW(B)) label="mutate B"
# Final read
res = @dspawn result(@R(A), @R(B)) label="read A,B"
fetch(res)
endwork (generic function with 1 method)Creating a LogInfo
In order to inspect code which makes use of DataFlowTasks, you can use the DataFlowTasks.@log macro to keep a trace of the various parallel events and the underlying DAG. Note that to avoid profiling the compilation time, it is often advisable to perform a "dry run" of the code first, as done in the example below:
# Context
A = ones(2000, 2000)
B = ones(3000, 3000)
# precompilation run
work(copy(A),copy(B))
# activate logging of events
log_info = DataFlowTasks.@log work(A, B)LogInfo with 5 logged tasks
The log_info object above, of LogInfo type, contains information that can be used to reconstruct both the inferred task dependencies, and the parallel execution traces of the DataFlowTasks. A summary of this information can be displayed using DataFlowTasks.describe, as illustrated next:
DataFlowTasks.describe(log_info; categories=["init", "mutate", "read"])• Elapsed time : 0.095
├─ Critical Path : 0.095
╰─ No-Wait : 0.017
• Run time : 0.761
├─ Computing : 0.139
│ ├─ init : 0.020
│ ├─ mutate : 0.102
│ ├─ read : 0.017
│ ╰─ unlabeled : 0.000
├─ Task Insertion : 0.000
╰─ Other (idle) : 0.622More powerful visualization capabilities, such as displaying the underlying DAG or showing the parallel trace of the tasks executed, are available upon loading additional packages such as GraphViz or Makie. These are discussed in the following sections, where we also explain in more detail the meaning of the numbers output by DataFlowTasks.describe.
When using @log, you typically want the block of code being benchmarked to wait for the completion of its DataFlowTasks before returning (otherwise the LogInfo object that is returned may lack information regarding the DataFlowTasks that have not been completed). In the example above, that was achieved through the use of fetch in the last line of the work function.
The logged execution time of each DataFlowTask is the time elapsed between the moment the code block passed to @dspawn starts executing, and the moment it finishes. This means that if the code block yields, the time recorded may not be representative of the actual time the task spent running.
DAG visualization
In order to better understand what this example does, and check that data dependencies were suitably annotated, it can be useful to look at the Directed Acyclic Graph (DAG) representing task dependencies as they were inferred by DataFlowTasks. The DAG can be visualized by creating a GraphViz.Graph out of it:
using GraphViz
GraphViz.Graph(log_info)
-->
<!-- Title: dag Pages: 1 -->
<svg width="240pt" height="188pt"
viewBox="0.00 0.00 240.24 188.00" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink">
<g id="graph0" class="graph" transform="scale(1 1) rotate(0) translate(4 184)">
<title>dag</title>
<polygon fill="white" stroke="transparent" points="-4,4 -4,-184 236.24,-184 236.24,4 -4,4"/>
<!-- 44767 -->
<g id="node1" class="node">
<title>44767</title>
<ellipse fill="none" stroke="black" stroke-width="2" cx="53.3" cy="-162" rx="36" ry="18"/>
<text text-anchor="middle" x="53.3" y="-158.3" font-family="Times,serif" font-size="14.00">init A</text>
</g>
<!-- 44769 -->
<g id="node2" class="node">
<title>44769</title>
<ellipse fill="none" stroke="black" stroke-width="2" cx="53.3" cy="-90" rx="53.09" ry="18"/>
<text text-anchor="middle" x="53.3" y="-86.3" font-family="Times,serif" font-size="14.00">mutate A</text>
</g>
<!-- 44767&%2345;>44769 -->
<g id="edge1" class="edge">
<title>44767&%2345;>44769</title>
<path fill="none" stroke="black" stroke-width="2" d="M53.3,-143.7C53.3,-135.98 53.3,-126.71 53.3,-118.11"/>
<polygon fill="black" stroke="black" stroke-width="2" points="56.8,-118.1 53.3,-108.1 49.8,-118.1 56.8,-118.1"/>
</g>
<!-- 44771 -->
<g id="node3" class="node">
<title>44771</title>
<ellipse fill="none" stroke="red" stroke-width="2" cx="115.3" cy="-18" rx="50.89" ry="18"/>
<text text-anchor="middle" x="115.3" y="-14.3" font-family="Times,serif" font-size="14.00">read A,B</text>
</g>
<!-- 44769&%2345;>44771 -->
<g id="edge2" class="edge">
<title>44769&%2345;>44771</title>
<path fill="none" stroke="black" stroke-width="2" d="M67.99,-72.41C75.71,-63.69 85.32,-52.85 93.85,-43.21"/>
<polygon fill="black" stroke="black" stroke-width="2" points="96.7,-45.28 100.71,-35.47 91.46,-40.64 96.7,-45.28"/>
</g>
<!-- 44770 -->
<g id="node4" class="node">
<title>44770</title>
<ellipse fill="none" stroke="red" stroke-width="2" cx="178.3" cy="-90" rx="53.89" ry="18"/>
<text text-anchor="middle" x="178.3" y="-86.3" font-family="Times,serif" font-size="14.00">mutate B</text>
</g>
<!-- 44770&%2345;>44771 -->
<g id="edge3" class="edge">
<title>44770&%2345;>44771</title>
<path fill="none" stroke="red" stroke-width="2" d="M163.37,-72.41C155.44,-63.61 145.56,-52.63 136.82,-42.92"/>
<polygon fill="red" stroke="red" stroke-width="2" points="139.41,-40.56 130.12,-35.47 134.21,-45.24 139.41,-40.56"/>
</g>
<!-- 44768 -->
<g id="node5" class="node">
<title>44768</title>
<ellipse fill="none" stroke="red" stroke-width="2" cx="178.3" cy="-162" rx="36.29" ry="18"/>
<text text-anchor="middle" x="178.3" y="-158.3" font-family="Times,serif" font-size="14.00">init B</text>
</g>
<!-- 44768&%2345;>44770 -->
<g id="edge4" class="edge">
<title>44768&%2345;>44770</title>
<path fill="none" stroke="red" stroke-width="2" d="M178.3,-143.7C178.3,-135.98 178.3,-126.71 178.3,-118.11"/>
<polygon fill="red" stroke="red" stroke-width="2" points="181.8,-118.1 178.3,-108.1 174.8,-118.1 181.8,-118.1"/>
</g>
</g>
</svg>
)
When the working environment supports rich media, the DAG will be displayed automatically. In other cases, it is possible to export it to an image using DataFlowTasks.savedag:
dag = GraphViz.Graph(log_info)
DataFlowTasks.savedag("profiling-example.svg", dag)Note how the task labels (which were provided as extra arguments to @dspawn) are used in the DAG rendering and make it more readable. In the DAG visualization, the critical path is highlighted in red: it is the sequential path that took the longest run time during the computation.
The run time of this critical path imposes a hard bound on parallel performances: no matter how many threads are available, it is not possible for the computation to take less time than the duration of the critical path.
Scheduling and profiling information
The collected scheduling & profiling information can be visualized using Makie.plot on the log_info object (note that using the GLMakie backend brings a bit more interactivity than CairoMakie):
using CairoMakie # or GLMakie to benefit from more interactivity
plot(log_info; categories=["init", "mutate", "read"])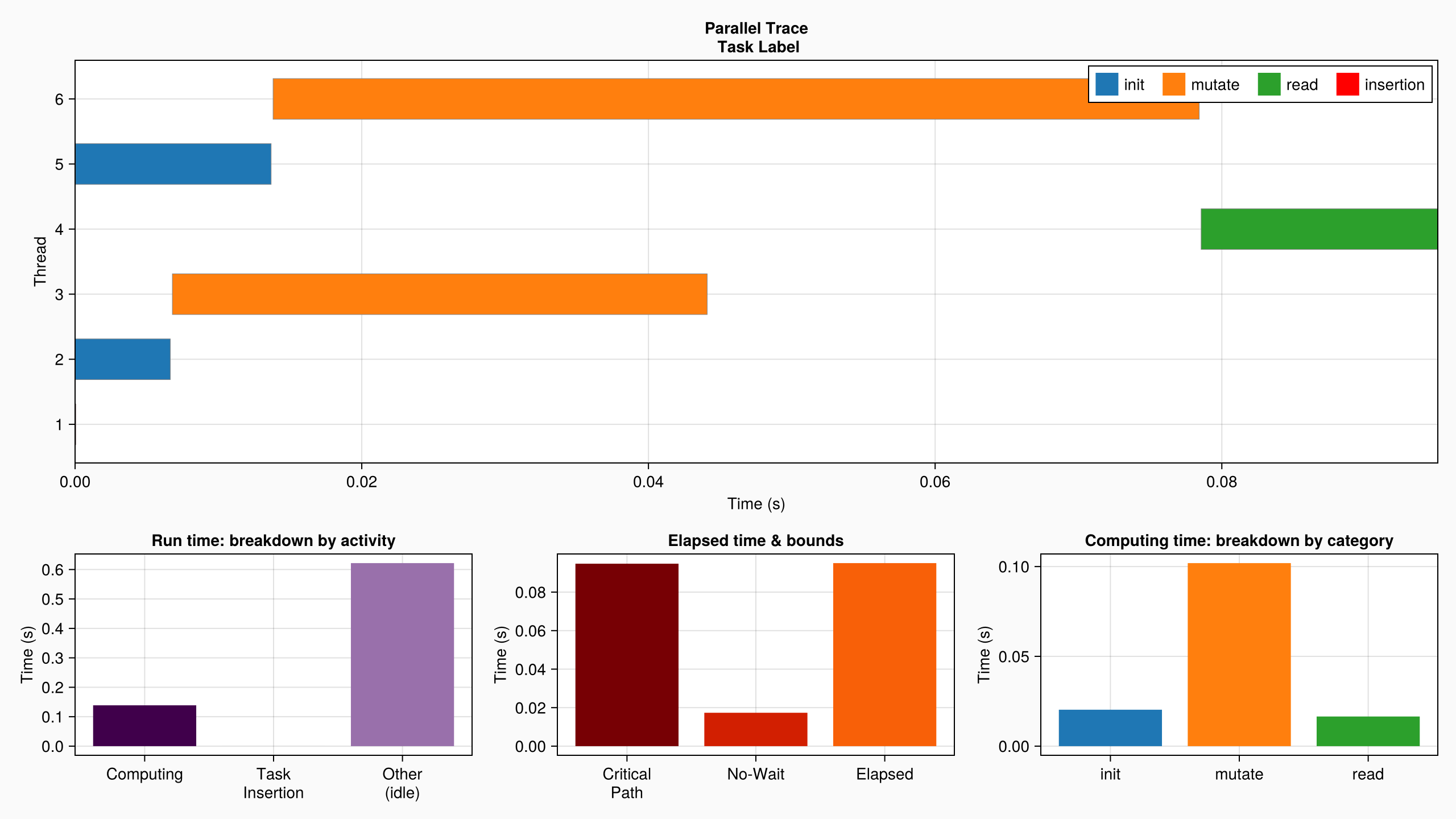
The categories keyword argument allows grouping tasks in categories according to their labels. In the example above, all tasks containing "mutate" in their label will be grouped in the same category.
Note : be careful with giving similar labels. If tasks have "R" and "RW" labels, and the substrings given to the plot's argument are also "R", and "RW", then all tasks will be in the category "R" (because "R" can be found in "RW"). Regular expressions can be given instead of substrings in order to avoid such issues.
Let us explore the various parts of this graph.
Parallel Trace
The main plot (at the top) is the parallel trace visualization. In this example there were two threads; we can see on which thread the task was run, and the time it took.
Even though tasks are grouped in categories by considering substrings in their labels, the full label is shown when hovering over a task in the interactive visualization (i.e. when using GLMakie instead of CairoMakie).
The plot also shows the time spent inserting nodes in the graph (which is part of the overhead incurred by the use of DataFlowTasks): these insertion times are visualized as red tasks. They are not visible for such a small example, but the interactive visualization allows zooming on the plot to search for those small tasks.
Also note that inserting tasks into the graph involves memory allocations, and may thus trigger garbage collector sweeps. When this happens, the time spent in the garbage collector is also shown in the plot.
Run time: breakdown by activity
A barplot in the bottom left corner of the window gives us information on the break-down of parallel run times (summed over all threads):
Computingrepresents the total time spent in the tasks bodies (i.e. "useful" work);Task Insertionrepresents the total time spent inserting nodes in the DAG (i.e. overhead induced byDataFlowTasks), possibly including any time spent in the GC if it is triggered by a memory allocation in the task insertion process;Other (idle)represents the total idle time on all threads (which may be due to bad scheduling, or simply arise by lack of enough exposed parallelism in the algorithm).
Elapsed time & bounds
A barplot in the bottom center of the window tries to present insightful information about the elapsed (wall-clock) time of the computation, and its limiting factors:
Elapsedrepresents the measured "wall clock time" of the computation; it should be larger than both of the bounds described below;Critical Pathrepresents the time spent in the longest sequential path in the DAG (shown in red in the DAG visualization). As said above, it bounds the performance in that even infinitely many threads would still have to compute this path sequentially;No-Waitrepresents the duration of a hypothetical computation in which all computing time would be evenly distributed among threads (i.e. no thread would ever have to wait). This also bounds the total time because it does not account for dependencies between tasks.
When looking for faster response times, this graph may suggest sensible ways to explore. If the measured time is close to the critical path duration, then adding more threads will be of no help, but decomposing the work in smaller tasks may be useful. On the other hand, if the measured time is close to the "without waiting" bound, then adding more workers may reduce the wall clock time and scale relatively well.
Computing time: breakdown by category
A barplot in the bottom right of the window displays a break-down of the total computing time (i.e. the total time spent on all threads while performing user-defined tasks), grouped by user-provided category as explained above.
When trying to optimize the sequential performance of the algorithm, this is where one can get data about what actually takes time (and therefore could produce large gains in performance if it could be optimized).